
Sitemize üye olarak beğendiğiniz içerikleri favorilerinize ekleyebilir, kendi ürettiğiniz ya da internet üzerinde beğendiğiniz içerikleri sitemizin ziyaretçilerine içerik gönder seçeneği ile sunabilirsiniz.
Sitemize üye olarak beğendiğiniz içerikleri favorilerinize ekleyebilir, kendi ürettiğiniz ya da internet üzerinde beğendiğiniz içerikleri sitemizin ziyaretçilerine içerik gönder seçeneği ile sunabilirsiniz.
Üyelerimize Özel Tüm Opsiyonlardan Kayıt Olarak Faydalanabilirsiniz

PEPE Coin ve Bu 2 Göğüs Coin İçin İhtar: FOMO Var!



Alibaba Group’un Akıllı Bilgisayar Enstitüsü‘nden araştırmacılar Linrui Tian, Qi Wang, Bang Zhang ve Liefeng Bo, yapay zekânın seçili metinleri okuyabilmelerini, okudukları metinlere nazaran de yüz tabirlerini akıcı biçimde değiştirebilmelerini sağlayan bir yapay zekâ olan EMO’yu tanıttı.
Ağız hareketleri, kelamlara uygun olarak değişiyor
EMO’nun en dikkat çeken yanı, bir fotoğrafı ya da görseli konuşturması değil, bunu yapan diğer çok sayıda uygulama görmüştük. Bu yapay zekâ aracının en kıymetli farkı, evvelce hazırlanmış konfigürasyonun dışında seslere nazaran de görselleri canlandırabilmesi. Ayrıyeten ağız hareketleri de kelamlara uygun olacak halde değişiyor. Yani görsel, tam manasıyla sese uygun olarak görüntüye dönüştürülüyor.
Bir öteki dikkat cazibeli özellik ise yapay zekâ aracının, ses kaynağına nazaran temposunu ayarlayabilmesi. Sakin sakin konuşma ile rap yapma ortasındaki farkı anlayabilen yapay zekâ, animasyonlarda da jest ve mimiklerin, ağız hareketlerinin temposunu buna nazaran ayarlıyor. Üstelik yapay zekâ, animasyon karakterlerini, yapay zekânın oluşturduğu görselleri ya da anime karakterlerini de konuşturmayı başarabiliyor.
Peki nasıl çalışıyor?
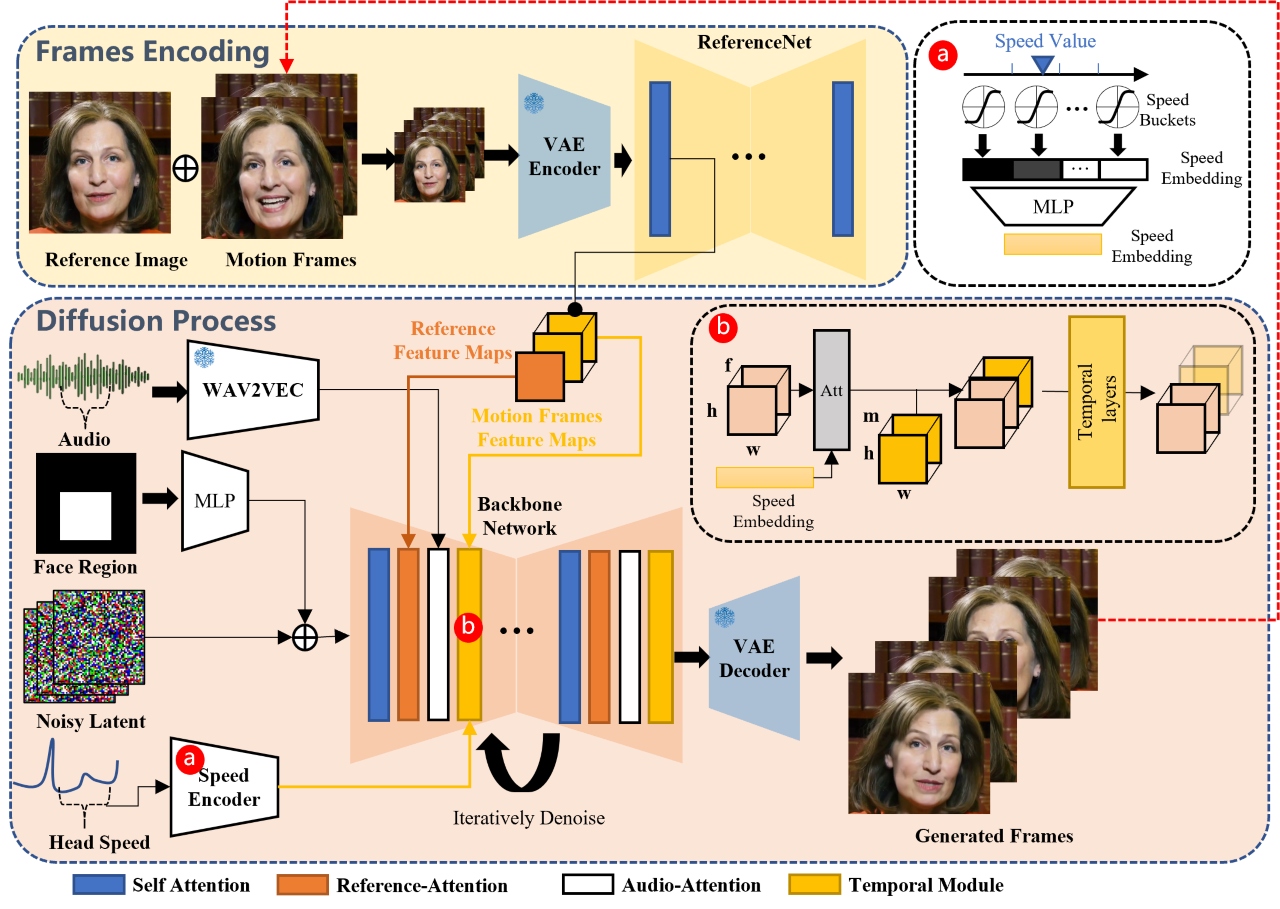
Araştırmacılar, yapay zekâ modelinin özünde iki kısımdan oluştuğunu belirtiyor. Bunlardan biri, görseli tanımlayıp referans görselden yola çıkarak hareketli kareleri oluşturuyor. Başkası ise ses evrakını tanımlayarak anahtar noktaları belirliyor. Sonrasında da anahtar noktalar ile görseller eşleştiriliyor. Yapay zekânın iki de denetim modülü bulunuyor. Bunlardan biri, görseldeki karakterin değişmeden kaldığına emin olurken oburu ise sesi denetim ediyor. Her iki taraftan gelen sonuçlar daha sonra birleştiriliyor.




















